FUSA-Net: Cross-Modal Music Retrieval
M.Sc. thesis — matching sheet music images to audio recordings using deep learning, without any human-labeled pairs.
RepositoryThe Problem
Finding the audio recording that matches a given sheet music page — or vice versa — is a task humans do naturally, but machines struggle with. Audio and sheet music live in completely different representational spaces: one is sound, the other is a visual document. Bridging them requires learning a shared space where both can be compared directly.
The Dataset
No large-scale public dataset existed for this task. I built PDMX-FUSA from scratch: 116,626 public-domain piano scores transformed into 291,648 training examples, each containing a synthesized audio recording, a high-resolution score image, and MIDI data — all aligned at the measure level.
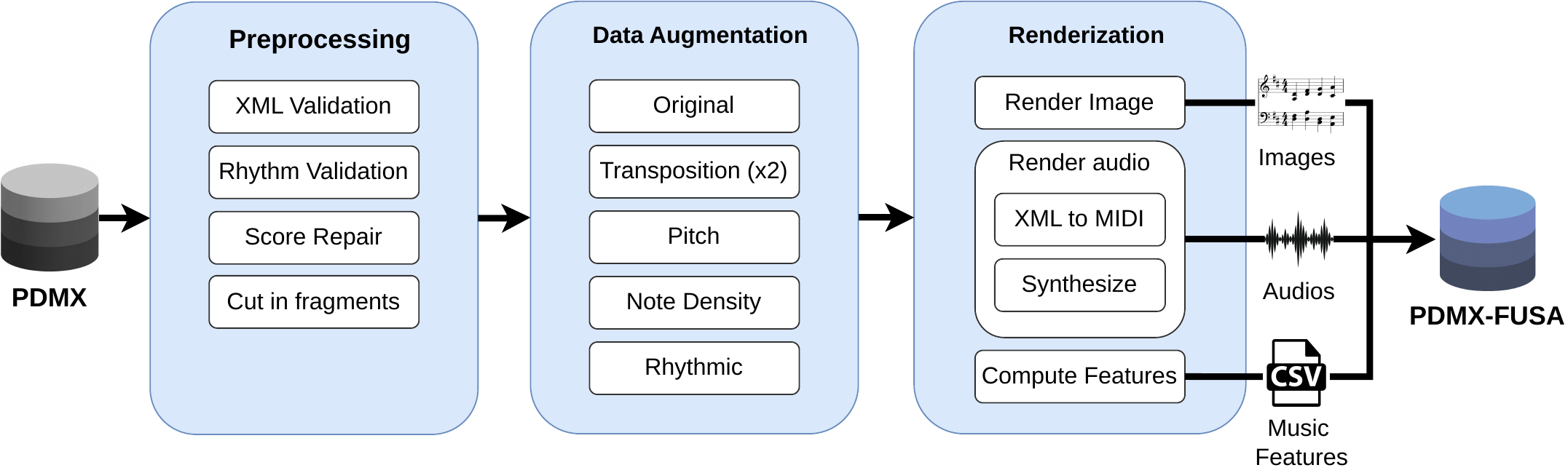
The Architecture
FUSA-Net is a dual-encoder model: one branch processes audio, the other processes score images. Both produce embeddings in a shared 512-dimensional space, trained with contrastive learning so that matching pairs are pushed together and non-matching pairs are pushed apart. Two design decisions made a significant difference. First, I used CCA (Canonical Correlation Analysis) to initialize the model in a geometrically favorable starting point, which made training 4.8× faster than standard approaches and more stable. Second, I added auxiliary prediction tasks — key, meter, polyphony — that force the shared space to organize itself around musically meaningful structure, not just identity matching.
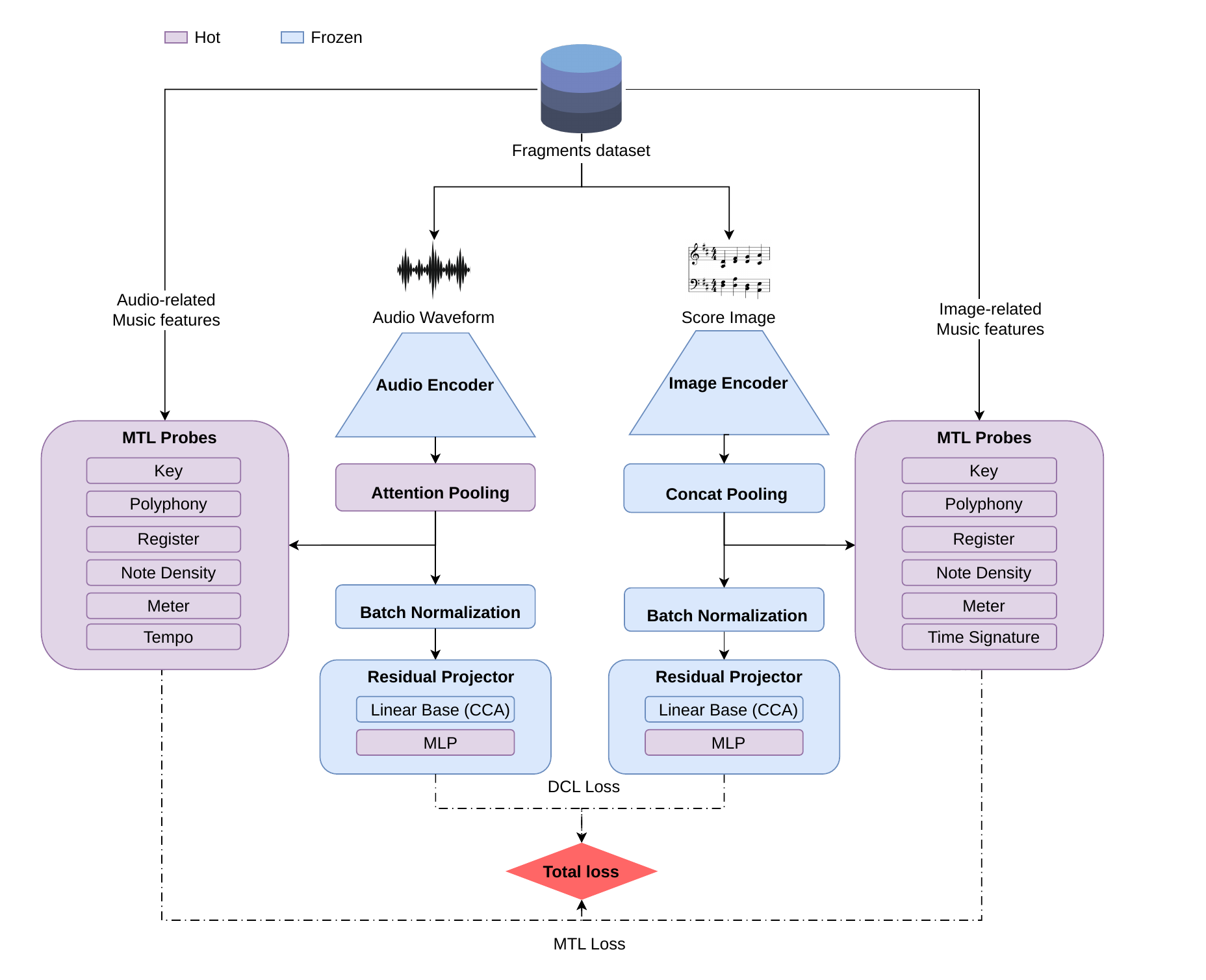
Results
Recall@1 = 66.87% · Recall@10 = 92.24% · Modality Gap = 0.036 In practical terms: given a sheet music page, the system finds the correct audio recording in its top 10 results more than 9 out of 10 times. Even when the top result is wrong, it is musically coherent — matching the correct polyphony 91.4% of the time and the correct meter 70.6% of the time.